Query Results — ChatGPT
Raw GPT-4o responses for each tracked query with brand mention extraction and visibility scoring per result.
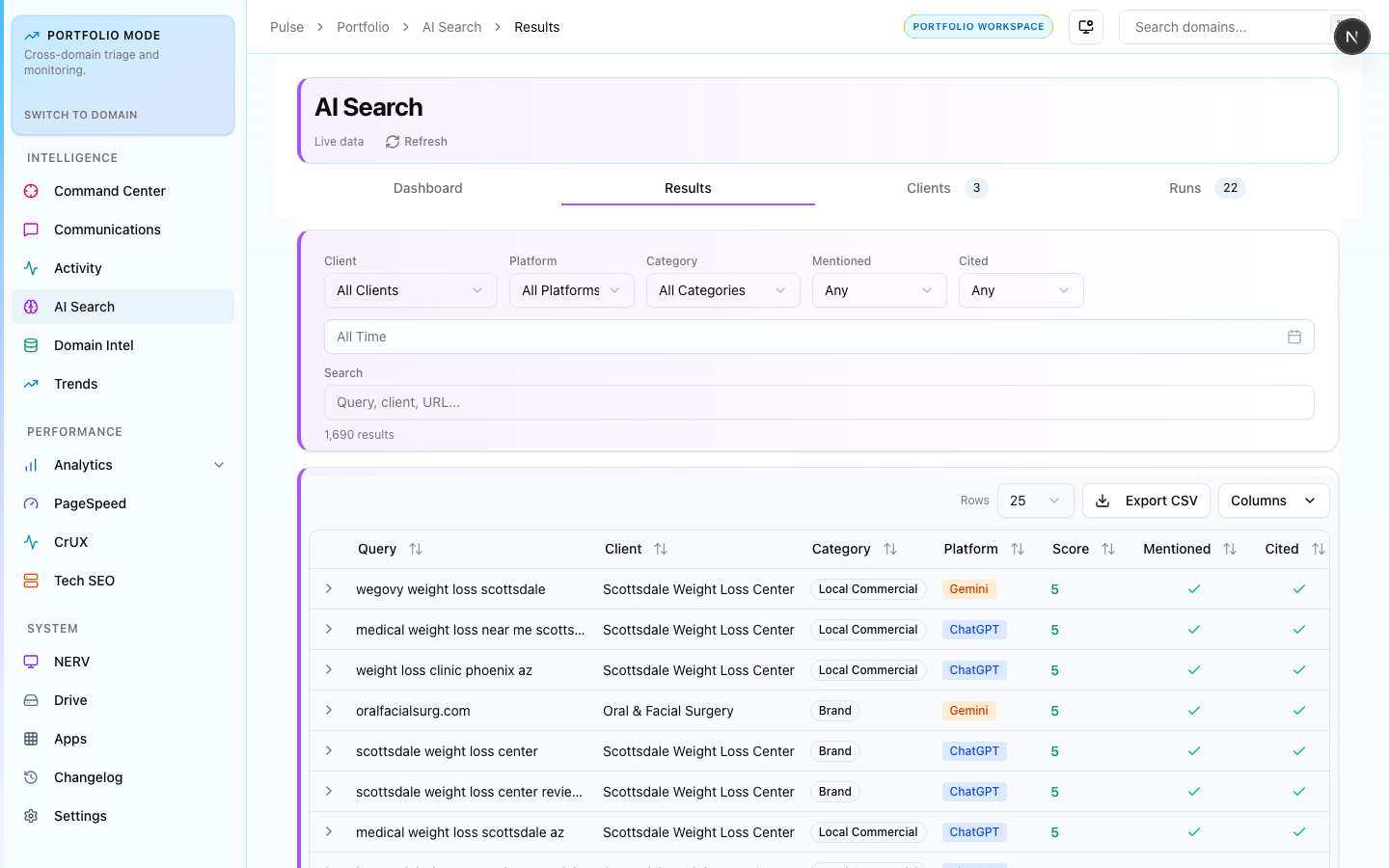
What It Shows
The ChatGPT query results view shows the actual GPT-4o responses for every tracked query, with brand mentions highlighted and scores assigned. This is the most granular view in the AI Search module.
For each query:
- The exact prompt sent to the API
- The full GPT-4o response text
- Highlighted brand/domain mentions with their score weight
- Date of last run
How the Pipeline Works
The pipeline sends each tracked query to the OpenAI API using a standardized prompt template designed to simulate how a patient might research a provider:
"What are the best [procedure] providers in [city]?" or "Who are reputable [specialty] doctors in [location]?"
Responses are parsed using a regex + LLM extraction pass to identify brand names, domain references, and contextual endorsements. The extraction is intentionally conservative — only clear, explicit mentions count toward the score.
Reading the Results
Responses vary significantly by query specificity. Generic queries ("best plastic surgeons in the US") rarely mention specific practices. Location-specific queries ("top rhinoplasty surgeons in Miami") are far more likely to surface individual brand names. The query library is tuned to favor the latter type for maximum signal quality.